From Monolithic to Modular: Scaling Semantic Routing with Extensible LoRA




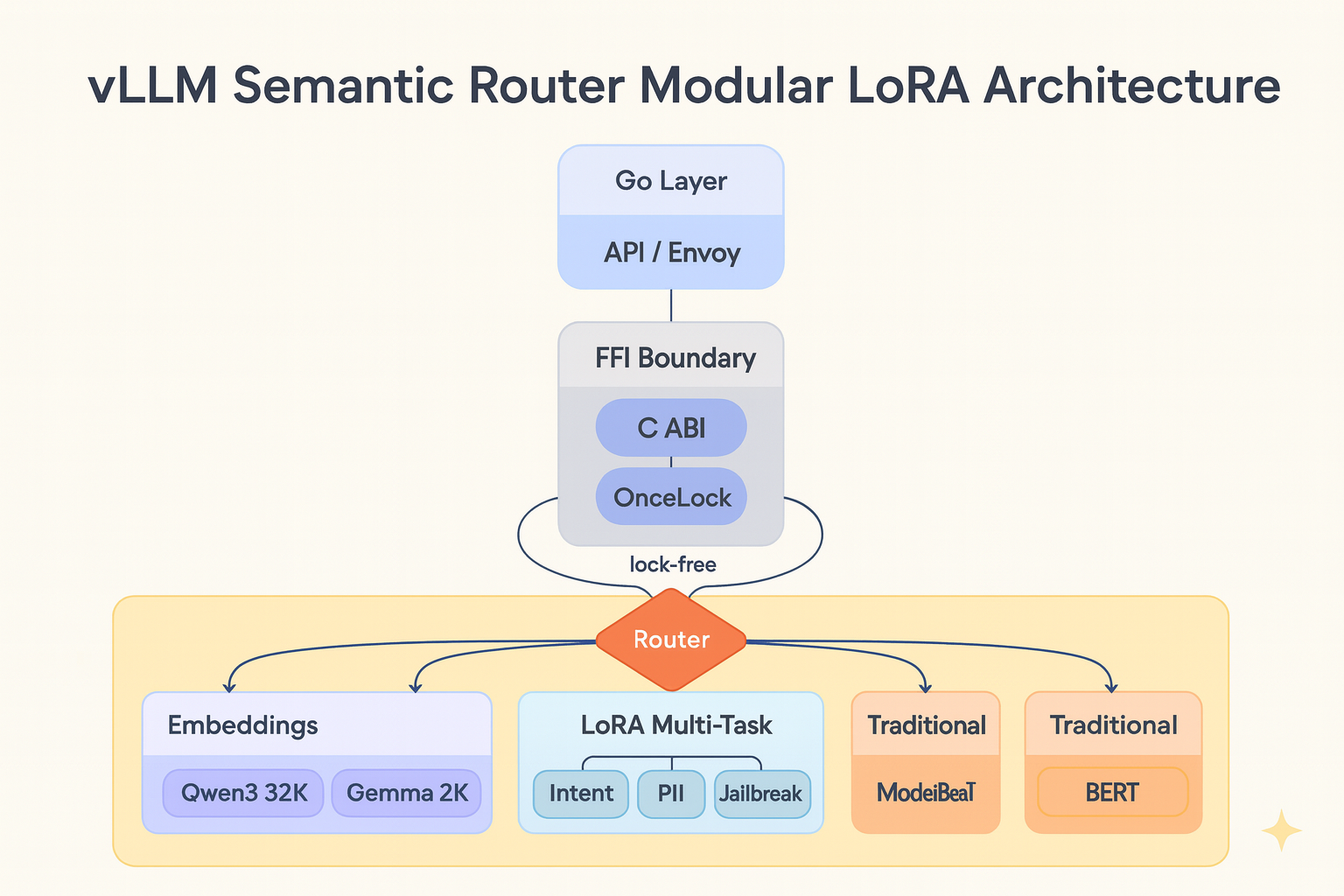
Semantic routing systems face a scaling challenge. When each classification request requires running multiple fine-tuned models independently, the computational cost grows linearly with the number of models. This post examines how a recent refactoring of the vLLM Semantic Router's Rust-based classification layer addresses this problem through architectural modularity, Low-Rank Adaptation (LoRA), and concurrency optimization.
Background: From BERT to a Modular System
The previous implementation relied primarily on BERT and ModernBERT for intent and jailbreak classification. While ModernBERT performs well for English text classification tasks, it has the following limitations:
- Language Coverage: The original ModernBERT's multilingual support is limited compared to models trained on more diverse datasets. (Note: mmBERT, a massively multilingual variant of ModernBERT supporting 1800+ languages, was released after this refactoring began and represents an alternative approach to the multilingual challenge)
- Context Length: While ModernBERT extends context to 8,192 tokens using RoPE (source), models like Qwen3-Embedding support up to 32,768 tokens, which is beneficial for very long document processing
- Model Coupling: Classification logic was tightly coupled to specific model architectures, making it difficult to add new models
These constraints motivated a broader refactoring that would enable the system to support multiple model types while maintaining performance. The modular architecture means that newer models like mmBERT can be integrated alongside Qwen3-Embedding and EmbeddingGemma, allowing the router to select the most appropriate model for each task.
Architectural Restructuring